Rapid Incident Response: How to Minimize Downtime in Production
Imagine you received an urgent Slack notification that bypassed your notification snooze. Your stomach drops as you realize there is a critical problem with your application. The next few hours are not going to be fun.
Uptime and high performance are key elements of a successful application. If users can’t effectively get what they need from your app, they’ll quit and find an alternative. Effective incident management in production environments is critical for minimizing downtime and maintaining customer satisfaction.
By adopting a structured approach to incident response, development teams can improve their ability to efficiently address and resolve issues as they arise. Here are some foundational strategies to streamline this process.

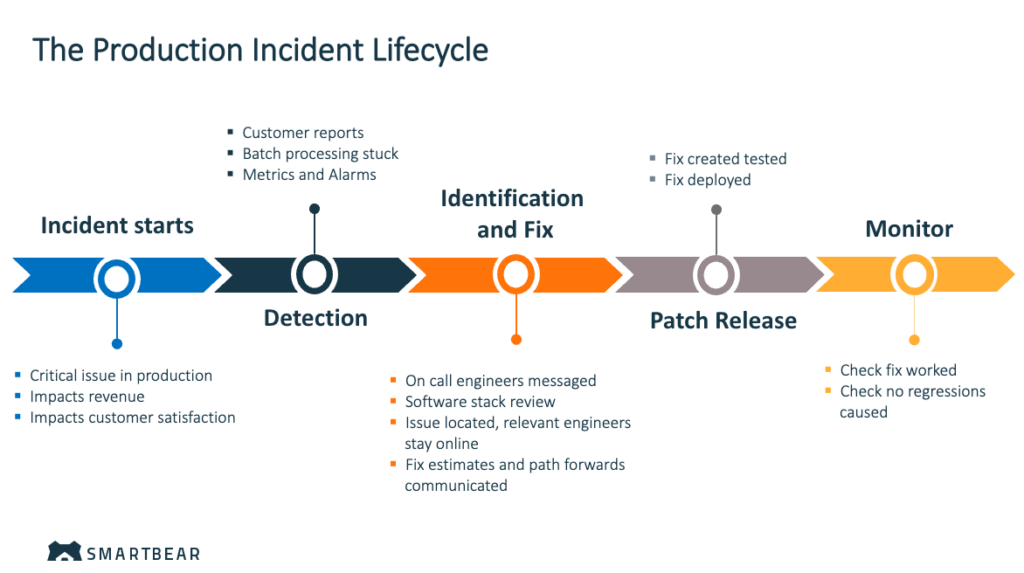
The Incident Lifecycle
Understanding the lifecycle of a production incident is key to developing a responsive incident management system. The stages typically include:
- Detection: Immediate detection is crucial. Implementing sophisticated monitoring systems that alert the team before customers notice issues can significantly improve response times.
- Diagnosis: Upon detecting an issue, automatically routing alerts to the relevant team based on the error’s nature and origin ensures the right experts are mobilized without delay.
- Resolution: Rapid resolution requires a coordinated effort. Teams often use collaborative approaches like “war rooms” to bring together developers, database administrators, and other stakeholders to brainstorm solutions and implement fixes.
- Post-mortem & monitoring: After an issue is resolved, conducting a thorough review to understand what went wrong and how future incidents can be prevented is crucial for refining response strategies.
Tools and Strategies for Efficient Incident Management
To maximize efficiency when dealing with production incidents, integrating the right tools and strategies into the workflow can be highly beneficial.
Centralized Information
Maintain a centralized, accessible repository of logs and system data to help teams quickly diagnose and address issues. This helps alerting and triage to occur more quickly.
Alert Routing
Removing white noise is key. By defining filters and setting trigger thresholds ahead of time, teams will be able to start working faster. This focused approach reduces the time to first response and speeds up the overall resolution process.
Code Ownership
Know who will fix an error before it happens. Configure and define assignment rules for direct alerts to specific teams based on the error location or type. Use tagging and filtering mechanisms to assign errors to teams responsible for specific code segments. This ensures the issues are quickly seen and there is team alignment throughout the debugging process.
Feature Flags
Get real-time observability by monitoring issues introduced by new features or experiment variants. Implementing feature flags to manage new deployments allows teams to enable or disable features without deploying new code. Then your team can make data-driven decisions about whether to roll out or roll back.
Iterative Improvement
Regularly update and refine incident response protocols based on lessons learned from past incidents to continuously improve response times and effectiveness.
By integrating these practices, organizations can ensure a swift and effective response to production incidents, minimizing impact on operations and maintaining high levels of customer satisfaction. These strategies help lay the foundation for a resilient incident management system that supports stable and reliable software environments.
If you are looking for a tool that allows you to seamlessly catch, fix, and prevent errors and performance issues, check out BugSnag. Sign up for a free 14-day trial, no credit card required. Want to see more? Sign up for a demo.